| �Ա���/��è�̳� |


|
| ������ɨһɨ |
 |
|
|
|
|
|
ɨ�ҹ���
|
| ұ���Կ����������������ҹ���Ʒ���ܴ���,����ǽƴ�Ӷ�������Ʊ���Է���8K�Կ���ƭ�� |
|
|
ұ���Կ�EDID������DP����matrox������8K�Կ�DP��ƭ��PCT���������Ե�ƴ�Ӷ������Ʒ�������PCV:˫����3��4��6��9��10��12���Կ�4K|8K��Ƶǽ,ͶӰƴ�Ӵ���ĻLEDС������ǽ����ָ����־���,�ڻ�/���/֤ȯ��������Ʊ������,���ͬ��ͨ���ŷ���ͬ��˳/�Ļ��ƾ�/���״�ʦ/���ǻ�,�����Զ����Ŷ�·����Ƶ����,��ҳ����һ�����ͷ�����ʾ��ͬ����,USB�Կ�����Displaylink��������.���� |
|
|
|
|
| AMD Instinct MI300X MI210 VS nvidia B100 A100 80G |
 |
| ��Ʒ���ۣ� |
|
| ��Ʒ�ߴ�(CM)�� |
|
| BIOS�� |
|
| Driver�������ӣ� |
|
| datasheet��� |
|
| procedure dwg�� |
|
| ������� |
6932 |
|
|
|
|
Instinct MI210 |
Nvidia A100 80GB PCIe |
Instinct MI250 |
Instinct MI250X |
|
Compute Units |
104 |
- |
208 |
220 |
|
Stream Processors |
6,656 |
6,912 |
13,312 |
14,080 |
|
FP64 Vector (Tensor) |
22.6 TFLOPS |
19.5 TFLOPS |
45.3 TFLOPS |
47.9 TFLOPS |
|
FP64 Matrix |
45.3 TFLOPS |
9.7 TFLOPS |
90.5 TFLOPS |
95.7 TFLOPS |
|
FP32 Vector |
22.6 TFLOPS |
9.7 TFLOPS (?) |
45.3 TFLOPS |
47.9 TFLOPS |
|
FP32 Tensor Float |
- |
156 | 312 TFLOPS |
- |
- |
|
FP32 Matrix |
45.3 TFLOPS |
19.5 TFLOPS |
90.5 TFLOPS |
95.7 TFLOPS |
|
FP16 |
181 TFLOPS |
312 | 624* TFLOPS |
362.1 TFLOPS |
383 TFLOPS |
|
bfloat16 |
181 TFLOPS |
312 | 624* TFLOPS |
362.1 TOPS |
383 TOPS |
|
INT8 |
181 TOPS |
624 | 1248 TOPS |
362.1 TOPS |
383 TOPS |
|
HBM2E ECC Memory |
64GB |
80GB |
128GB |
128GB |
|
Memory Bandwidth |
1.6 TB/s |
1.935 TB/s |
3.2 TB/s |
3.2 TB/s |
|
Form-Factor |
PCIe card |
PCIe card |
OAM |
OAM |
|
��1�� CUDA�� CUDA ��һ�ֽ� GPU ��Ϊ���ݲ��м����豸����Ӳ����ϵ������Ҫ����ͼ ��ѧ API�����Dz����˱Ƚ��������յ��� C ���Խ��п�����������Ա�ܹ�������Ϥ�� C ���ԱȽ�ƽ�ȵش�CPU ���ɵ� GPU ��̡���������GPU ��ȣ�֧�� CUDA �� GPU �ڼܹ������������ĸĽ���1��������ͳһ�����ܹ������Ը�����Ч�����ù�ȥ �ֲ��ڶ�����ɫ����������ɫ���ļ�����Դ��2��������Ƭ�ڹ����洢��������Ľ�ʹ �� CUDA �ܹ�����������ͨ�ü��㣬���� 2008 ���ƻ����AMD���� IBM �Ƴ��� OpenCL ��Դ����GPGPU ��ͨ�ü�������Ѹ�ٷ�չ��
2) �����;�����ģ�GPGPU �Ĵ���Ӳ�����㵥Ԫ�����¸ߴ����Ĵ洢����ܹ��ṩ ǿ��ļ���������ͬʱ��Ծ�������;����������������ṩ��������Ƶļ��ٿ�֧ �֣�ʹ�� GPGPU �ܹ���ֵ�������Ӳ��������Դ�ʹ洢��Դ,ʵ�ָ����µľ����� �㡣Ϊ�˽�һ������������������ܣ������� NVIDIA �� AMD �� GPGPU ������ȫ �µ������;�����Ĵ�����������㣬���һ�֧�ֶ��־��ȣ�ʹ�� GPGPU �ܹ���Ӧ ��������粻ͬ��������ͬӦ�õľ�������
3) HBM �洢������һ��DRAM ���������ͻ���ڴ����������ƿ����HBM ��һ������ ��CPU/GPU �ڴ�оƬ��ͨ�������DDR ��������3D �ѵ����CPU/GPU ��װ��һ ����ʵ�ִ���������λ����DDR ������С�ͨ�����Ӵ�������չ�ڴ��������ø��� ��ģ�ͣ�����IJ�����������ļ�������ĵط����Ӷ������ڴ�ʹ洢����������� ���ӳ١�
4) ���Ƶ�Ԫ��CPU �����������������Ĵ��������Ϳ��Ʋ����ȣ��Ǽ����������Ϳ� �ƺ��ģ�ע��ͨ�������������ֲ�ͬ���������ͣ�����CPU �ṹ�д־�������� �������Ƶ�·�ʹ洢��Ԫ��ֻ���ٲ����������ʵ�����㹤��������CPU �ڴ��ģ�� �м��������ϼ�Ϊ���� |
|
GPU�ؼ������Աȱ� |
| |
NVIDIA |
AMD |
|
��Ʒ�ͺ� |
Tesla V100 |
Tesla A100 |
H100 |
MI100 |
MI 250 |
MI 250X |
MI 300 |
| |
|
|
|
|
|
|
|
|
GPU |
GV100 |
GA100 |
GH100 |
Arcturus |
Aldebaran |
Aldebaran |
|
|
�ܹ� |
Volta |
Ampere |
Hopper |
CNDA 1.0 |
CNDA 2.0 |
CNDA 2.0 |
CNDA 3.0 |
|
SM |
80 |
108 |
132 |
|
|
|
|
|
SP |
5,120CUDA |
6,912CUDA |
16,896CUDA |
7,680 |
13,312 |
14,080 |
|
|
����/������ĵ�Ԫ |
640 |
432 |
528 |
480 |
832 |
880 |
|
|
GPU��ƵƵ��/MHz |
1,530 |
1,410 |
1,775 |
1,502 |
1,700 |
1,700 |
|
|
FP32��Ԫ��ֵ
(GFLOPS) |
15,670 |
19,490 |
67,000 |
23,100 |
45,260 |
47,870 |
|
|
FP64��Ԫ��ֵ
(GFLOPS) |
7,834 |
9,746 |
34,000 |
11,500 |
45,260 |
47,870 |
|
|
������Ԫ/�����ֵ
(TFLOPS,FP16) |
125 |
312 |
1,979 |
184.6 |
362 |
383 |
|
|
�洢���ӿ� |
4096-bit HBM2 |
5120-bit HBM2e |
5120-bit HBM3 |
4096-bit HBM2 |
8192-bit HBM2e |
8192-bit HBM2e |
HBM3 |
|
�洢����С |
16GB |
40GB |
80GB |
32GB |
128GB |
128GB |
128GB |
|
TDP/�� |
300 |
250 |
700 |
300 |
560 |
560 |
|
|
���������/10�� |
21.1 |
54.2 |
80 |
|
58 |
58 |
146 |
|
оƬ��С/mm² |
815 |
826 |
814 |
750 |
700+ |
700+ |
|
|
����/nm |
12FFN |
7 |
4 |
7 |
6 |
6 |
5/6 |
2024�������������㿨AMD MX300X�Ա�NVIDIA B100�����Ƚ�ͼ
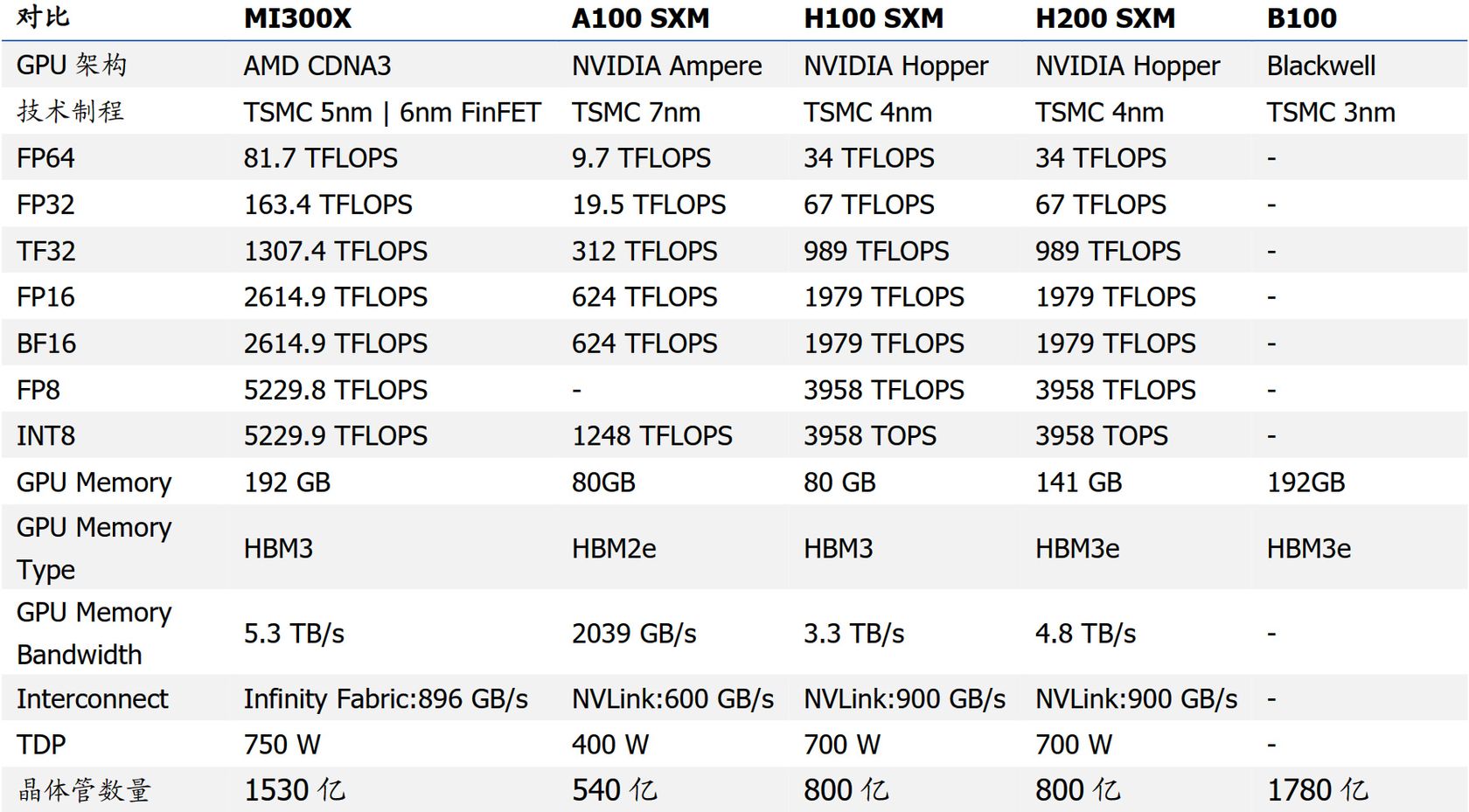
|
|
|
|
AMD Radeon Instinct Accelerators |
�� |
�� |
�� |
�� |
�� |
�� |
�� |
�� |
�� |
�� |
|
ACCELERATOR NAME |
AMD INSTINCT MI400 |
AMD INSTINCT MI300 |
AMD INSTINCT MI250X |
AMD INSTINCT MI250 |
AMD INSTINCT MI210 |
AMD INSTINCT MI100 |
AMD INSTINCT MI60 |
AMD INSTINCT MI50 |
AMD INSTINCT MI25 |
AMD INSTINCT MI8 |
AMD INSTINCT MI6 |
|
CPU Architecture |
Zen 5 (Exascale APU) |
Zen 4 (Exascale APU) |
N/A |
N/A |
N/A |
N/A |
N/A |
N/A |
N/A |
N/A |
N/A |
|
GPU Architecture |
CDNA 4 |
Aqua Vanjaram (CDNA 3) |
Aldebaran (CDNA 2) |
Aldebaran (CDNA 2) |
Aldebaran (CDNA 2) |
Arcturus (CDNA 1) |
Vega 20 |
Vega 20 |
Vega 10 |
Fiji XT |
Polaris 10 |
|
GPU Process Node |
4nm |
5nm+6nm |
6nm |
6nm |
6nm |
7nm FinFET |
7nm FinFET |
7nm FinFET |
14nm FinFET |
28nm |
14nm FinFET |
|
GPU Chiplets |
TBD |
8 (MCM) |
2 (MCM) |
2 (MCM) |
2 (MCM) |
1 (Monolithic) |
1 (Monolithic) |
1 (Monolithic) |
1 (Monolithic) |
1 (Monolithic) |
1 (Monolithic) |
|
1 (Per Die) |
1 (Per Die) |
1 (Per Die) |
|
GPU Cores |
TBD |
Up To 19,456 |
14,080 |
13,312 |
6656 |
7680 |
4096 |
3840 |
4096 |
4096 |
2304 |
|
GPU Clock Speed |
TBD |
TBA |
1700 MHz |
1700 MHz |
1700 MHz |
1500 MHz |
1800 MHz |
1725 MHz |
1500 MHz |
1000 MHz |
1237 MHz |
|
FP16 Compute |
TBD |
TBA |
383 TOPs |
362 TOPs |
181 TOPs |
185 TFLOPs |
29.5 TFLOPs |
26.5 TFLOPs |
24.6 TFLOPs |
8.2 TFLOPs |
5.7 TFLOPs |
|
FP32 Compute |
TBD |
TBA |
95.7 TFLOPs |
90.5 TFLOPs |
45.3 TFLOPs |
23.1 TFLOPs |
14.7 TFLOPs |
13.3 TFLOPs |
12.3 TFLOPs |
8.2 TFLOPs |
5.7 TFLOPs |
|
FP64 Compute |
TBD |
TBA |
47.9 TFLOPs |
45.3 TFLOPs |
22.6 TFLOPs |
11.5 TFLOPs |
7.4 TFLOPs |
6.6 TFLOPs |
768 GFLOPs |
512 GFLOPs |
384 GFLOPs |
|
VRAM |
TBD |
192 GB HBM3 |
128 GB HBM2e |
128 GB HBM2e |
64 GB HBM2e |
32 GB HBM2 |
32 GB HBM2 |
16 GB HBM2 |
16 GB HBM2 |
4 GB HBM1 |
16GB GDDR5 |
|
Memory Clock |
TBD |
5.2 Gbps |
3.2 Gbps |
3.2 Gbps |
3.2 Gbps |
1200 MHz |
1000 MHz |
1000 MHz |
945 MHz |
500 MHz |
1750 MHz |
|
Memory Bus |
TBD |
8192-bit |
8192-bit |
8192-bit |
4096-bit |
4096-bit bus |
4096-bit bus |
4096-bit bus |
2048-bit bus |
4096-bit bus |
256-bit bus |
|
Memory Bandwidth |
TBD |
5.2 TB/s |
3.2 TB/s |
3.2 TB/s |
1.6 TB/s |
1.23 TB/s |
1 TB/s |
1 TB/s |
484 GB/s |
512 GB/s |
224 GB/s |
|
Form Factor |
TBD |
OAM |
OAM |
OAM |
Dual Slot Card |
Dual Slot, Full Length |
Dual Slot, Full Length |
Dual Slot, Full Length |
Dual Slot, Full Length |
Dual Slot, Half Length |
Single Slot, Full Length |
|
Cooling |
TBD |
Passive Cooling |
Passive Cooling |
Passive Cooling |
Passive Cooling |
Passive Cooling |
Passive Cooling |
Passive Cooling |
Passive Cooling |
Passive Cooling |
Passive Cooling |
|
TDP (Max) |
TBD |
750W |
560W |
500W |
300W |
300W |
300W |
300W |
300W |
175W |
150W |
|
|
|
|









